Data APIs
Focus on user value, not the toil of consuming data
You need to consume data from static files via an API. You may want to:
Work with your existing tools
Connect your data directly to PowerBI, Tableau, or other business tools to avoid vendor lock-in and ensure everyone works from the same source of truth, no matter their preferred platform.
Build exactly what you need
Create interactive, responsive and visually appealing applications on top of your data that fit your exact business needs with today's user-friendly development tools and AI.
Future proof your data
APIs are here to stay. Whether you're sharing with partners or the public, migrating to new systems, or building future applications, ensure your data is already in the right format.

You don't have to:
- Spend weeks of effort creating an ETL pipeline.
- Develop and operate a secure and performant data service.
- Maintain and pay for infrastructure.
tap will turn those files into ready-to-integrate HTTP APIs in seconds:
- Zero backend configuration. No servers to manage.
- Clean, join, enrich your data using familiar SQL queries.
- Work with CSV, JSONL, Parquet and other files of any size.
- Everything you expect from an API, like OpenAPI documentation, built-in security and monitoring.
- High performance with fast, optimised queries.
- Pricing model that you don't have to think twice about.
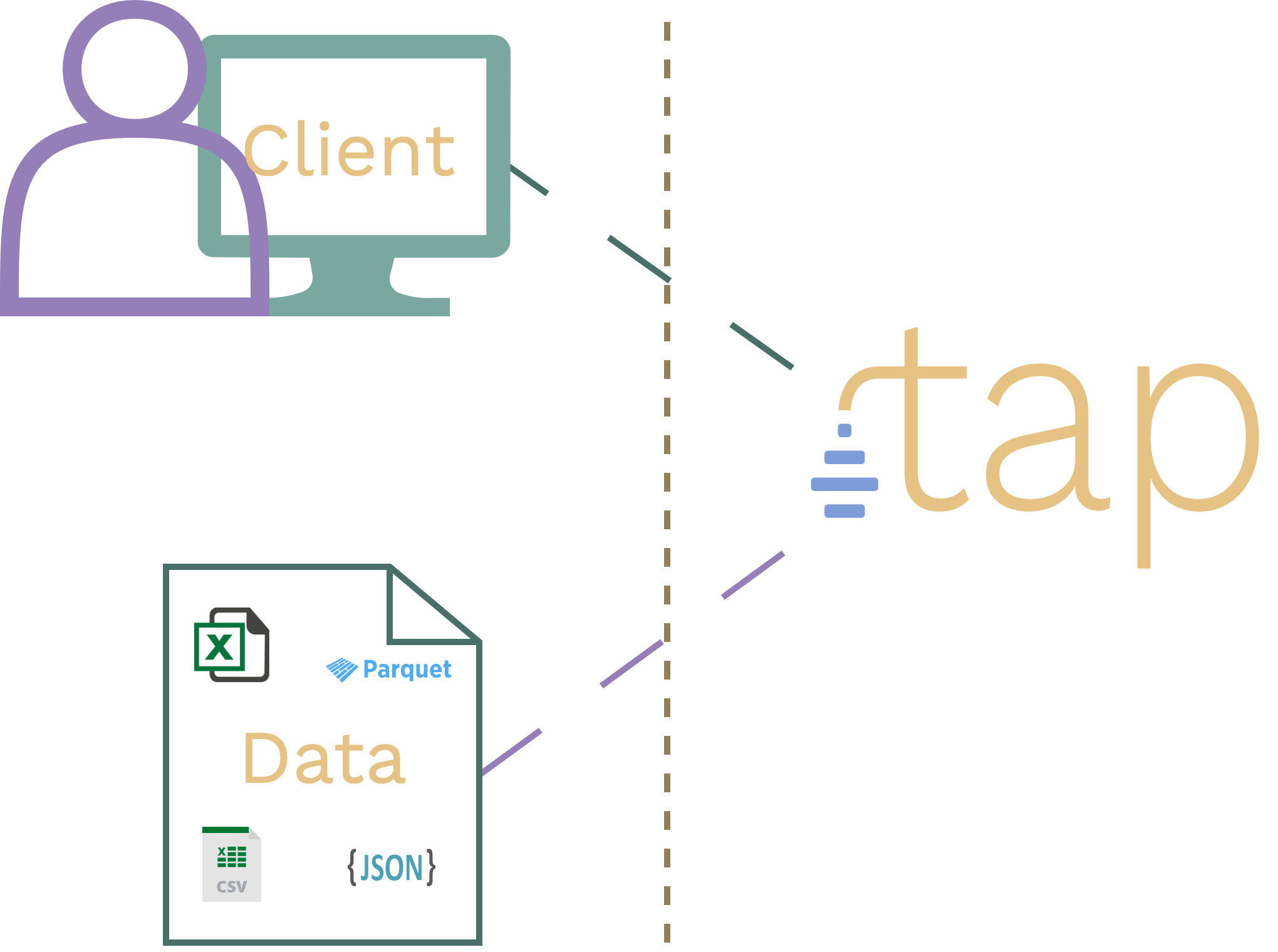
How does tap compare to alternative approaches?
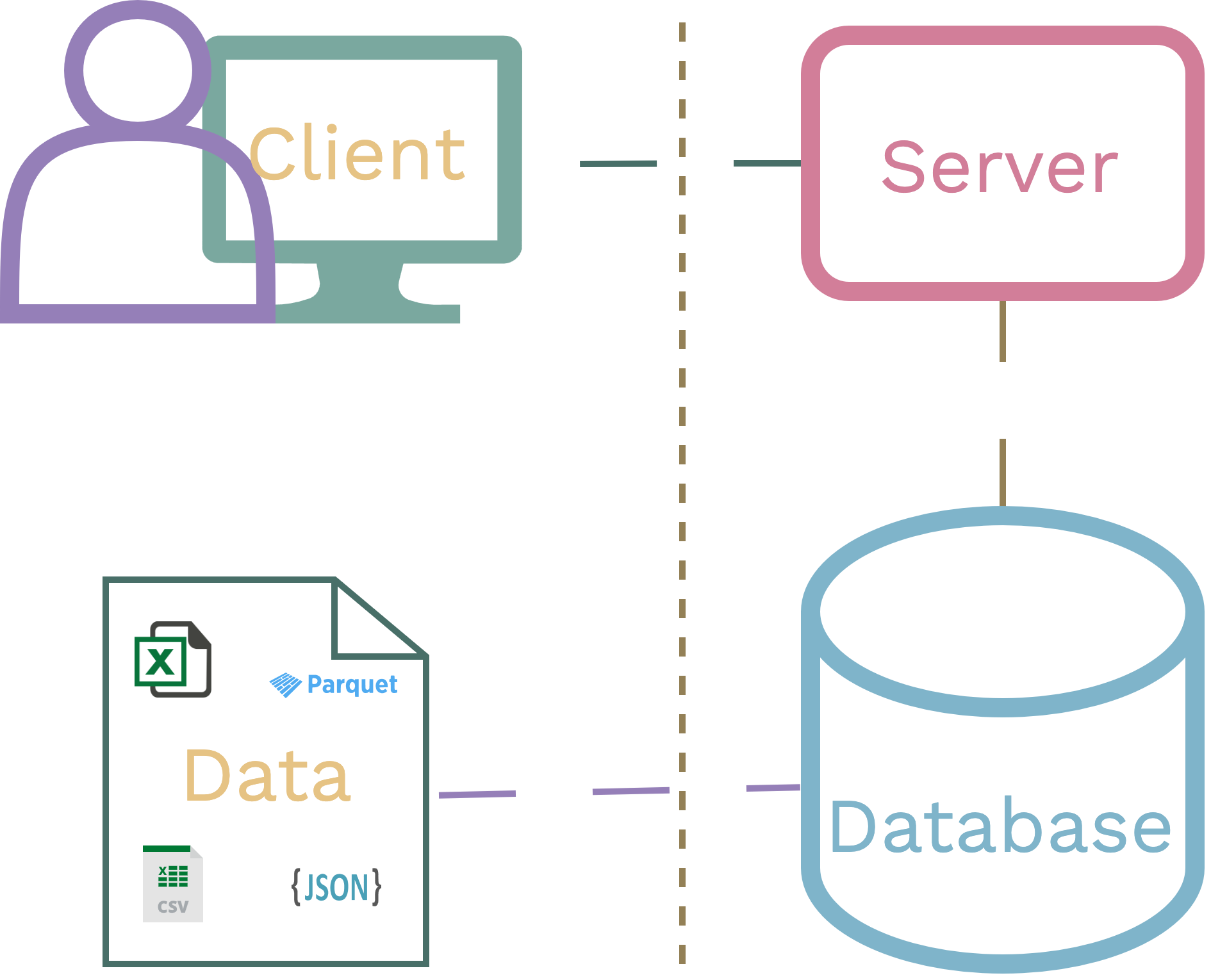
In a 3-tier architecture that powers the vast majority of applications today, you would need to:
- Spin up a database.
- Determine and manage a data schema with optimised indexes based on your access needs.
- Extract data from your file(s), transform the data to match your schema, and load it into a database in a reproducible way.
- Create an API and deploy to a server to return data from your database.
- Add authentication to protect your data.
- Operate and pay for your server and database infrastructure.
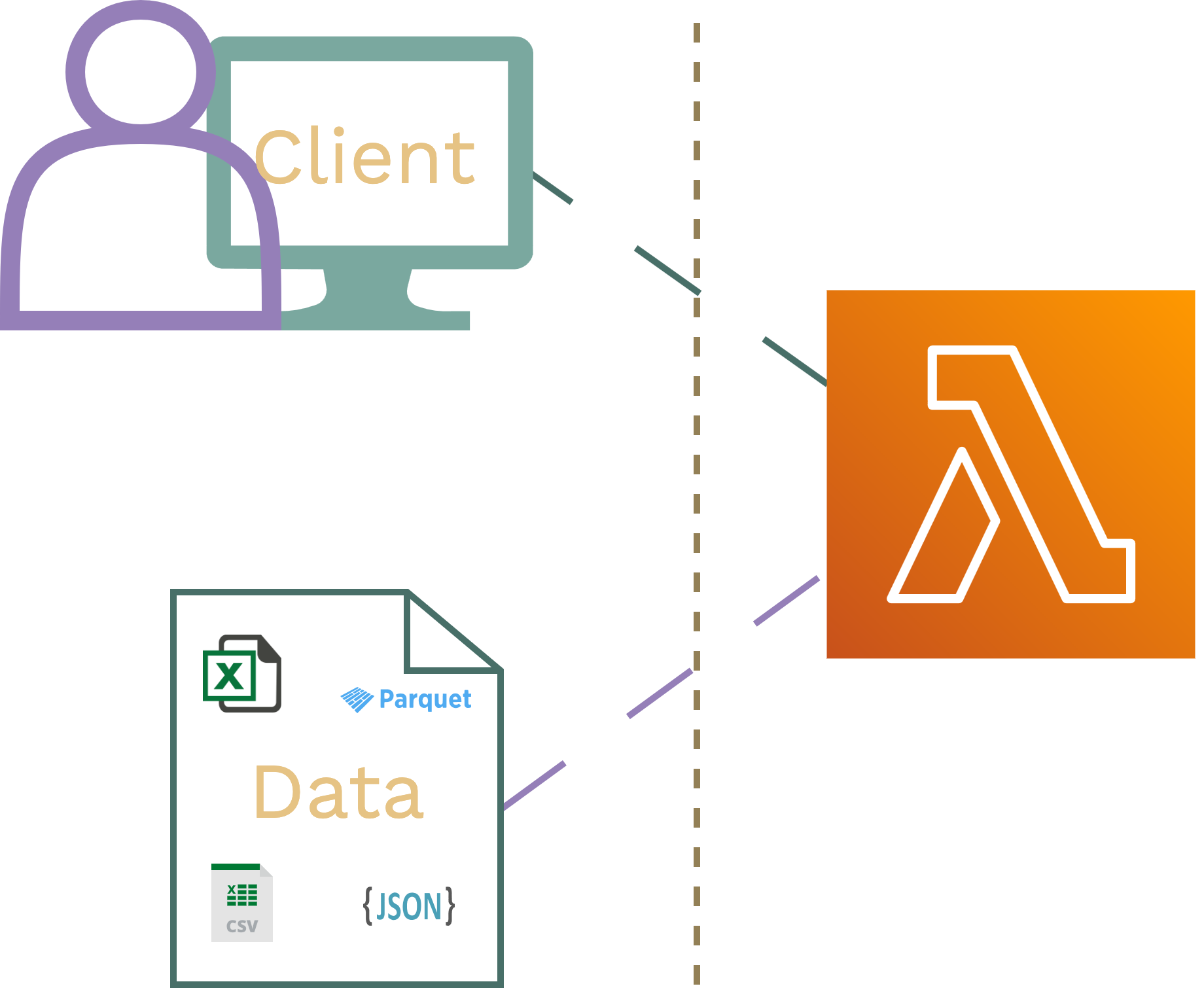
When choosing a possibly lower effort implementation, such as exposing the files directly from a function in a serveless architecture, you'd face the following limitations and challenges:
- File size limits.
- Maintaining some kind of reproducible ETL pipeline for potential initial data transformation and subsequent updates.
- Subpar performance for even relatively small files.
- Having to implement or pay for authentication to protect your data.
- Enable cost-controls or network policies to protect against denial-of-wallet attacks.

Do you have data files you need to turn into an API?
tap is an easy to use and fire-and-forget tool enabling your data-centric application needs.
Start building immediately • No credit card required